É de conhecimento geral que computadores trabalham com números, especificamente números na base binária. Sabendo disso, como podemos representar o texto que eu estou escrevendo apenas com conjuntos de 0s e 1s? Como o computador, trabalhando apenas com números, consegue lidar com textos?
Tabelas de caracteres (Charsets)
Para realizar essa tarefa, tabelas de caracteres (charsets) são utilizadas. Com essas tabelas, algum caractere pode ser mapeado para algum número. Esse número que será armazenado e manipulado pelos programas que lidam com textos. Mas como esse mapeamento é feito?
ASCII
Uma das tabelas de caracteres mais antigas que se tem conhecimento é a ASCII (American Standard Code for Information Interchange). Esta tabela contém todos os números e os caracteres usados pelo idioma inglês, onde cada um desses caracteres é mapeado para um número e esse número é convertido diretamente para a base binária, sendo uma representação bastante simples. Os números vão de 0 a 127, ou seja, qualquer caractere da tabela ASCII pode ser representado em até 7 bits, o que é menos que 1 byte (1 byte = 8 bits).
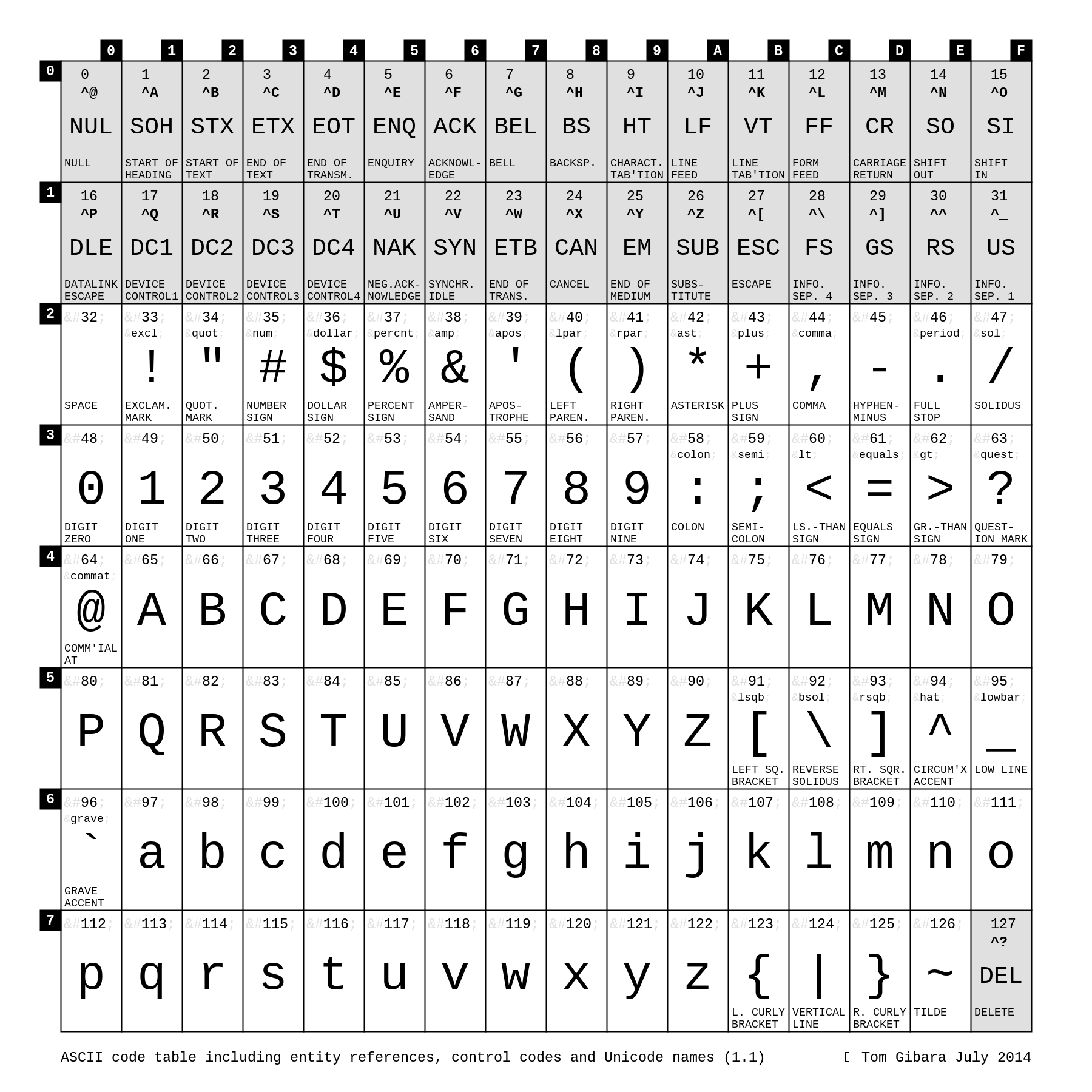
Isso funcionava muito bem para textos que usavam inglês como idioma (ou algum idioma com o mesmo conjunto de caracteres). Porém, diversos outros idiomas possuem caracteres que não estão representados nesta tabela. Caracteres acentuados, por exemplo, não estão na tabela ASCII. Como representar textos em português, por exemplo?
Extended ASCII
Como pudemos ver na imagem da tabela ASCII, os valores vão de 0 a 127. Isso pode ser representado com 7 bits.
Como foi citado no capítulo anterior, todos os caracteres da tabela ASCII podem ser representados com até 7 bits. Sendo assim, temos 1 bit "sobrando" para cada caractere completar 1 byte.
Pensando nisso, surgiram diversas outras tabelas de caracteres fazendo uso deste bit adicional para representar outros caracteres. Desta forma é criada a tabela ASCII estendida: Extended ASCII ou EASCII
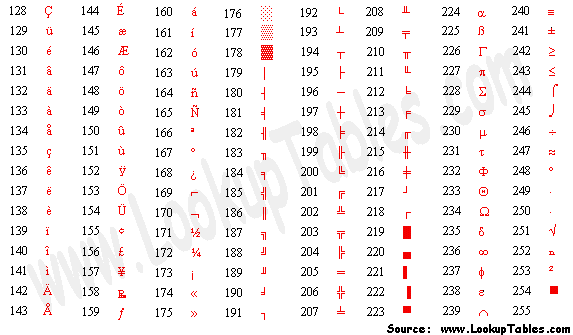
Ao mesmo tempo, outros idiomas que possuem seu alfabeto sem nenhuma semelhança com o inglês (como japonês ou russo) utilizavam tabelas completamente diferentes para representar seus caracteres.
Ascensão da Web
O uso de tabelas diferentes funcionou muito bem enquanto os arquivos ficavam apenas em um computador ou eram compartilhados em redes locais (como de universidades). Porém, conforme a Web nasceu e cresceu, o compartilhamento de arquivos se tornou uma tarefa trivial. Como eu, no Brasil, poderia enviar um documento para o Egito, usando o alfabeto grego? Essa tarefa era simplesmente impossível.
Unicode
Pensando em ter uma forma unificada de representar todos os caracteres conhecidos no mundo, em 1991 foi criada o Unicode Consortium. Essa iniciativa trabalha e tem encontros frequentes para garantir que há suporte a todos os idiomas e caracteres conhecidos pela humanidade, incluindo emojis. Parece um trabalho enorme e realmente é.
Emojis, por exemplo, foram sugeridos à iniciativa em meados de 2000, porém apenas após 2007 eles foram incorporados ao Unicode.
Então, se formos supersimplificar (muito), podemos dizer que o Unicode Consortium criou um grande charset, ou seja, uma grande tabela de caracteres. Porém, essa "tabela" é gigante! Como representar estes números enormes de forma eficiente?
Encodings
Aqui entram os encodings. O número 128 512 (em hexadecimal, 1F600) representa o emoji de sorriso (😀). Esse número 128 512 pode ser representado de várias formas dependendo do encoding selecionado para tal arquivo. Alguns encodings compatíveis com Unicode são: - UTF-8 - UTF-16 - UTF-32
Inicialmente eu acreditava que a diferença entre eles era apenas o número de bits utilizado, sendo assim UTF-8 poderia representar menos caracteres já que usa menos bits. Não é o caso. Todos eles podem consumir um número variável de bits os organizando de forma diferente. Cada encoding pode ser mais vantajoso dependendo do cenário. Para representar textos (como esse que escrevo) e mensagens transferidas pela rede, UTF-8 é o mais recomendado e utilizado, visto que sua organização permite que os caracteres mais comuns ocupem o menor espaço possível. Já UTF-16 ocupa menos espaço representando caracteres com números maiores na "tabela" unicode.
Conclusão
É comum utilizarmos funções de conversão de encoding sem entender bem o que estamos fazendo e muito provavelmente todo mundo que desenvolve software para a web já se deparou com o seguinte problema:

Entender como funcionam charsets e encodings de texto além de ser interessante e divertido, pode nos ajudar a compreender melhor problemas deste tipo e principalmente encontrar a solução de forma mais simples.
Creio que seja seguro afirmar que a grande maioria dos textos que tratamos como desenvolvedores utiliza UTF-8 como encoding e neste artigo nós entendemos o motivo disso e como o tratamento de textos evoluiu até chegar a esse ponto.
Se você quiser aprender mais sobre esse assunto, pode considerar assinar a Alura. Lá existem treinamentos que tratam sobre charsets, encoding, manipulação de strings e muito mais. Caso pretenda estudar na Alura, neste link você tem um desconto de 15%.
